The House of Data Series: Enablement
This paper focuses on how data programs get adopted — training, knowledge management, coaching, and the change management work required to turn built capabilities into used ones. It does not cover the technical design of those capabilities or governance policy — those are addressed in the Data Architecture, DataOps, and Compliance whitepapers.
.png)

Get the Best of Data Leadership
Stay Informed
Get Data Insights Delivered
House of Data Series
Every strong data program is built like a house. Data Architecture forms the foundation — the platforms, pipelines, and operating model that everything else depends on. Seven domain pillars rise from that foundation, each one essential to a complete data program: Data Quality, Privacy, Data Security, DataOps, Compliance, Data Enablement, and Data Consumption. Data Literacy runs across all seven as a connecting beam, ensuring people at every level can read, interpret, and act on data. At the top, People & Leadership sets the direction, accountability, and culture that holds the whole structure together.
This series of whitepapers covers each component of the House of Data in depth. Each paper was written by Jim Barker (Principal, Data Strategy), with support from a practitioner with direct experience in that domain. Together, they form a practical guide to building data programs that earn — and keep — trust.
This paper covers Data Enablement — the function that ensures people can actually use the data capabilities the organization has built. Without structured enablement, even the best data products fail to achieve adoption.
Data enablement
Data enablement is a term that is often misused. Some corporations who have struggled with data governance and looked for a new term have used data enablement as a title for their data governance program. Other debates have broken out and resumed the data governance/data enablement debate outright. This paper takes a different view: data enablement is the helpful part of the data governance program and is used to propel AI, analytics, and digital modernization efforts forward.
In this paper we will:
- Define data enablement
- Align coaching, mentoring, and knowledge management to data enablement
- Cover top-of-mind data enablement capabilities
- Introduce telemetry to continue data enablement for continuous improvement
- Describe the role of data enablement in data trust
A quick scan of data enablement in a search engine — or what AI provides — returns a varied set of definitions that are self-serving, or aligned to a re-organization of data enablement to be the whole term for a hybrid view of data governance and data management. This is not correct.
Data enablement defined
Data enablement should be defined as: the practice of empowering people to use data confidently and effectively by providing accessible data, intuitive tools, and the knowledge needed to make data-driven decisions.
Data enablement should be the cross-functional set of actions that always introduce, support, and promote data capabilities. It should at a minimum provide an introduction of new data capabilities, which includes roll-out materials, job aids, support documents for solutions, and include telemetry and follow-up to promote the new and existing capabilities.
Leverage the idea from Davenport of "Learn Before," "Learn While," and "Learn After Doing." Use this enablement of capability to expand business value and increase return on investment (ROI) of these new data capabilities. Further, by putting in systems that support the use of data, capabilities will grow. To be sure, continue to serve the data audience to find out what is needed to increase users' satisfaction and make a difference.
This area of enablement is one area in the rollout of new data capabilities. As we invest in new capabilities, this is the set of activities as we begin to use new data capabilities.
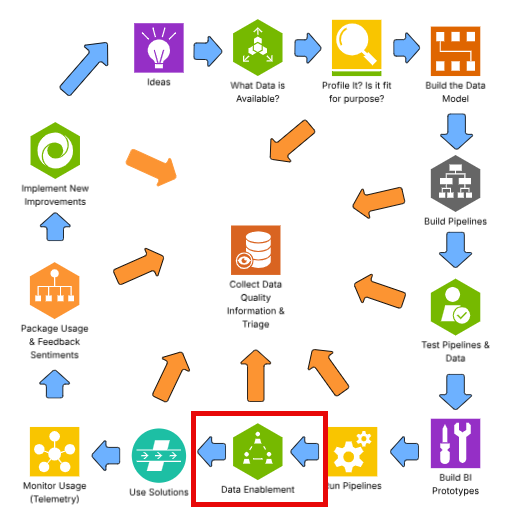
To be successful at enabling, knowledge work needs to be done across the development lifecycle. Business purpose, business and technical metadata needs to be compiled, job aids and training docs need to be built, and the consumers of this capability need to be thought of front, center, and always.
In the overall set of activities, enabling staff is the most important activity for success. Think of this idea when considering Data Enablement 101 below.
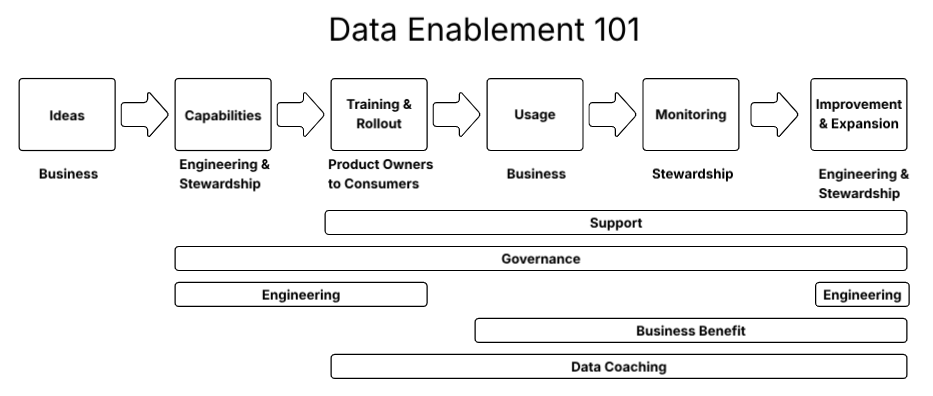
This diagram shows how the enablement outcomes will be achieved through a set of actions from ideation to business value. To be successful, the DataOps team will execute on a run basis and address any issues proactively, and address any and all issues that occur. The governance team will continue to support the business through building job aids, training materials, business support offerings, and encouraging data coaching. Data coaching will assist the growth of user adoption of these new solutions to drive business benefits.
Enablement tools and assets
The key to enablement is the assets and training materials. The following tasks list off some key tools to consider using. They are broken down in three categories: (1) Training Tools; (2) Knowledge Management Tools; (3) Six Sigma Tools.
As you enable your staff, consider asking these questions to understand the mindset of the staff you are about to enable on the new capabilities:
- What are the available skills and training needs of your organization?
- What resources are available, most notably personnel, time, and budget?
- What is the organization's readiness for this change to support it?
- What were the data collection and analysis capabilities before this new offering?
Once those questions are answered, take some time to consider your current state. Ask these questions to determine how to move forward:
- What type of waste is most highly possible?
- Are quality defects the primary concern?
- How complex were your processes before and after this new capability?
- What data is currently available vs. what is being added?
The answers to these questions will help to determine what tools are needed and build your enablement plan. The following is a list of commonly used tools that firms use to achieve successful enablement and successful use of data capabilities. No firm uses all of these. Use this as a guide to possible tools you could build out. The tools to use should be heavily dependent on the answers to the questions above.
Data coaching
The idea of data coaching is to develop a stable of "official" coaches that are publicized to be helping folks move forward in particular areas of expertise. People that can help and be viewed as not being judged, there to help. Additionally, encouraging coaching or "helpers" inside business teams can be very helpful. That friend-of-a-friend concept makes a big difference.
When providing enablement, having some "official" data coaches identified helps. Additionally, the evolution of coaches or helpers happens normally. Some kudos to people helping is a nice touch that makes a big difference, encouraging supporting your data peers as a positive influence on your organization.
Six Sigma tools for data programs
In the list of possible assets there is a column for Six Sigma tools. Many people in the data profession have limited experience or skills in the Six Sigma space, a space normally thought of as continuous improvement for manufacturing organizations, so many of these tools can generate improvement for data professionals. This notion is based on DMAIC. DMAIC stands for Define, Measure, Analyze, Improve, and Control. Just reading each of those pieces, data professionals immediately offer up a "wait a minute, that is what I do all the time." Due to this we incorporate many aspects of Six Sigma in this series of white papers. Here is a table of what each of those tools mean:
Enabling: a guide
This section is meant to be a helpful guide to executing enablement. It was written based on feedback on a number of projects, and hopefully helps you as you establish your development standard for enablement. It is provided with the numbered lines being the enablement steps, and the check boxes being pre-requisite tasks for successful completion of a project.
Note: we use the term "data capability" but it could be a variety of other terms such as data product, dashboard, executive information system, AI analytical solution, etc.
Steps to enable on a new data capability
Build out pre-requisites:
- List of original ideas by person/team/role
- Define target audience
- Determine use case
- Establish desired outcomes
- Listing of potential data objects
- Detailed list of leveraged data objects
- Populated metadata for each physical table, column, report, and dashboard
- Developed data pipelines for each data asset (file or table)
- Available lineage for each delivered object
- Documented test cases with results
- List of developed analytic output for alerts, AI analytics, dashboards, digital assets, and reports
- Developed analytic output for alerts, AI analytics, dashboards, digital assets, and reports certified
- Run book for daily/weekly/monthly processes
- How-to for each outcome asset: developed analytic output for alerts, AI analytics, dashboards, digital assets, and reports
- How-to for opening up outcome assets
- Additional how-to's the user community will require (this list should grow over time based on lessons learned)
- Write-up labs for training/rollout
Enablement steps:
- Determine format and timing of onboard training
- From the target audience list and requested user list
- Identify the right window for training: weeks/days/times
- Schedule the onboard training
- Host the onboard training
- Share the labs
- Share the wide range of training and job aids to new users
- Promote the new capability with core users and the broader community
- Follow up on lab completion
- Host follow-up training as necessary
- Check on use of new capabilities
- Follow up to build user adoption
- Promote the capability further
- Survey the user base or collect similar information with other methods
- Report out adoption numbers, and work for help to increase adoption rate
Remember the steps following enablement, and take action to maximize use of the new capability: (1) Use solutions; (2) Monitor usage; (3) Package usage and feedback sentiment; (4) Detail new improvement; (5) Develop and implement improvements; (6) Promote improvements.
Coaching
To be successful, the governance and enabling team should recruit, train, and support a set of official data coaches to support all new users. It should also include providing a mechanism that simplifies the finding of coaches that can provide some help.
AI trust in enablement
Most AI capabilities have people involved, either "human involved" or "human managed," so they require enablement on how to use the AI capability, how to share concerns, and generally all questions regarding the use of data in AI.
During the rollout of new analytical capabilities, AI capabilities, or business processes, time should be spent to educate users on:
- The process
- Appropriate use of data for AI
- Sharing of data from and into AI
- Identifying data quality needs
- Vision of data you can use and share, or need to be concerned about
It is only with training on data sensitivity and AI that we can truly achieve AI Trust.
Role of Bigeye for data enablement
Bigeye's technology is important in building, operating, and rolling out new data capabilities. There are three or four areas that are worth considering when enabling staff.
First, use lineage charts to show what data flows to what solutions. This can be a "show quick and move on" approach, but showing data flows will help some, while it may confuse others, so be careful with it.
Second, showing the browser extension to the audience to see where they can see data quality, and that they can trust the data, is very helpful.
Third, showing data quality results to the user in other places, such as inside a catalog or in the Bigeye UI, can be helpful. The data that you make available in data quality dashboards or reports can also be very valuable.
Which of these to use is up to you. Remember the goal of enablement is to get people started with confidence, so find the right balance between educating on provenance of data and trust in data quality, and making it easy for the end user to use the data right away. That is a critical decision.
Summary
Data enablement is the set of activities to roll out new data capabilities and data products for business success. It includes building the assets necessary for successful knowledge transfer and help tools. It should also include establishing data coaches, and focusing on continuous improvement.
References
Adjeddine, K., & Lundqvist, M. (2016). Policy in the data age: Data enablement for the common good. McKinsey & Company.
Horvitz, E., & Mitchell, T. (2020). From data to knowledge to action: A global enabler for the 21st century. arXiv. https://arxiv.org/abs/2008.00045
IBM. (n.d.). What is data enablement? https://www.ibm.com/think/insights/data-enablement
Inside Automation. (n.d.). Data enablement: Optimize your business. https://insideautomation.net/data-enablement-optimize-your-business-aw-aug/
DataQG. (n.d.). The 5 pillars of data enablement. https://dataqg.com/articles/the-5-pillars-of-data-enablement/
GRC World Forums. (n.d.). Beyond protection: The rise of data enablement.
TDAN (The Data Administration Newsletter). (n.d.). Making the case for data enablement rather than data governance.
Thomson Reuters & Pitchly. (2023). The next big thing: Data enablement. https://www.thomsonreuters.com/en-us/posts/wp-content/uploads/sites/20/2023/01/The-Next-Big-Thing_Data-Enablement-Pitchly.pdf
Monitoring
Schema change detection
Lineage monitoring
Jim Barker

.png)
.png)

.png)