This paper focuses on the platforms, pipelines, and operating models that form the foundation of a data program. It covers how architectural decisions affect every capability built on top of them, but does not go deep on data quality monitoring, governance policy, or team structure — those are covered in the Data Quality, Compliance, and People & Leadership whitepapers.
Join hundreds of data professionals who subscribe to the Data Leaders Digest for actionable insights and expert advice.
Join The AI Trust Summit on April 16
A one-day virtual summit on the controls enterprise leaders need to scale AI where it counts.
Get the Best of Data Leadership
Subscribe to the Data Leaders Digest for exclusive content on data reliability, observability, and leadership from top industry experts.
Get the Best of Data Leadership
Subscribe to the Data Leaders Digest for exclusive content on data reliability, observability, and leadership from top industry experts.
Stay Informed
Sign up for the Data Leaders Digest and get the latest trends, insights, and strategies in data management delivered straight to your inbox.
Get Data Insights Delivered
Join hundreds of data professionals who subscribe to the Data Leaders Digest for actionable insights and expert advice.
House of Data Series
Every strong data program is built like a house. Data Architecture forms the foundation — the platforms, pipelines, and operating model that everything else depends on. Seven domain pillars rise from that foundation: Data Quality, Privacy, Data Security, DataOps, Compliance, Data Enablement, and Data Consumption. Data Literacy connects them all as a beam. At the top, People & Leadership provides direction and accountability.
This series of whitepapers covers each component in depth. Each paper was written by Jim Barker (Principal, Data Strategy), with support from a practitioner with direct experience in that domain.
Data Leadership Data Literacy Data Quality Privacy Data Security DataOps Compliance Data Enablement Data Consumption Data Architecture
This paper covers Data Architecture — the foundation on which every other data capability is built. Architecture isn't just the software stack. It's the combination of data governance, data management, the operating model that connects them, and the methodology frameworks that guide how a mature data program is run. Without a solid architectural foundation, the pillars above it are unstable.
Data architecture
Data programs require a solid architecture of applications, a well understood operating model for those applications, and a unified approach to the data program. In the "House of Data," architecture is the foundation that stabilizes the program.
One key distinction that needs to be understood is the difference between Data Governance and Data Management.
Data Governance is defined as: the processes and standards for managing data to ensure its accuracy, consistency, security, and usability across an organization. This approach uses defined policies, roles, and data quality measurements to improve decision-making and ensure regulatory compliance. Gartner emphasizes an "adaptive" model, which allows organizations to tailor governance approaches to different business scenarios rather than using a one-size-fits-all strategy.
Data Management is defined as: a technology-enabled discipline that involves practices, architectural techniques, and tools for managing data consistently and efficiently across an enterprise to meet the needs of applications and business processes. This includes ensuring the uniformity, accuracy, stewardship, and accountability of data assets, often through collaboration between business and IT.
Another way to envision these and their relationship is the idea of a data coin. On one side of the coin is data governance — the business-led set of activities executed to focus on data governance, privacy, security, and the set of policies and standards necessary for a well-run data program. On the other side is Data Management, the wide-ranging set of activities that IT owns, supporting the data governance effort. By illustrating this as a coin, the relationship between the two is understood to be very close, aligned to make any movement performed in unison between business and IT resources.
It is critical to have data governance and data management aligned to build the momentum necessary for a well-run data machine.
Running industry-leading data processes requires people, data quality, data privacy, data security, DataOps, Policies & Oversight, and Enablement to achieve great and reliable consumption.
Consumption will be based on AI, analytics, and digital transformation. To run these data programs there are a set of methodologies that have been documented by organizations like DAMA, DGPO, EDM Associates, and advocated by the most vocal of evangelists.
The DAMA Wheel
DATA GOVERNANCE Data Architecture Data Modeling and Design Data Storage and Operations Data Security Data Integration and Interoperability Document and Content Management Reference and Master Data Data Warehousing and Business Intelligence Metadata Data Quality
The DAMA wheel isn't a data governance wheel, as it is often misconstrued, but rather a diagram that identifies many of the areas managed by a data program, tied together with data governance operations. For more information on the DAMA wheel, consult DMBOK — the Data Management Body of Knowledge — or see this reference: dama.org.
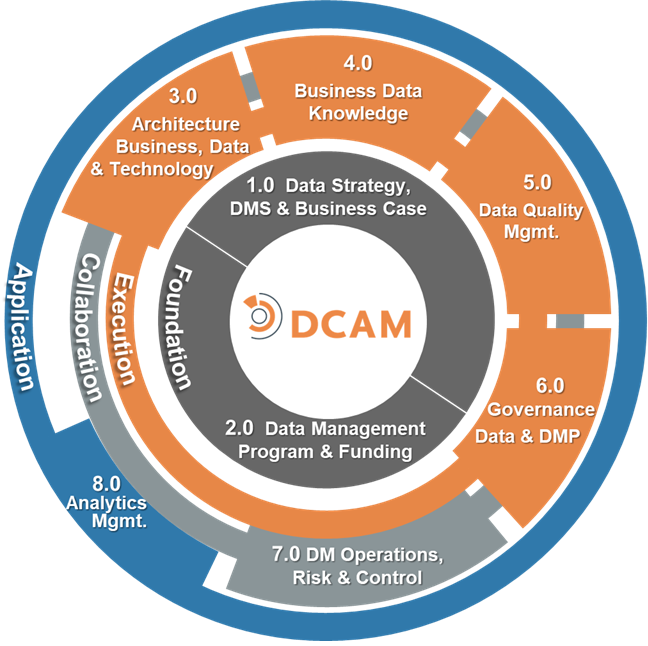
The DCAM Framework
The DCAM framework (EDM Associates) is used to depict how to run a data program. It identifies data governance and data control as the sixth and seventh step of operations. It is recommended to view data governance as more centrally focused; however, many of the activities defined by DCAM are great concepts that require focus and attention. For more information on DCAM, check out: edmcouncil.org/frameworks/dcam/.
DGPO
DGPO (Data Governance Professionals Association) is an organization that aligns to the data governance and stewardship function. DGPO collects and shares best practices, aligns professionals, and is singularly focused on data governance. For more information on DGPO, check out: dgpo.org.
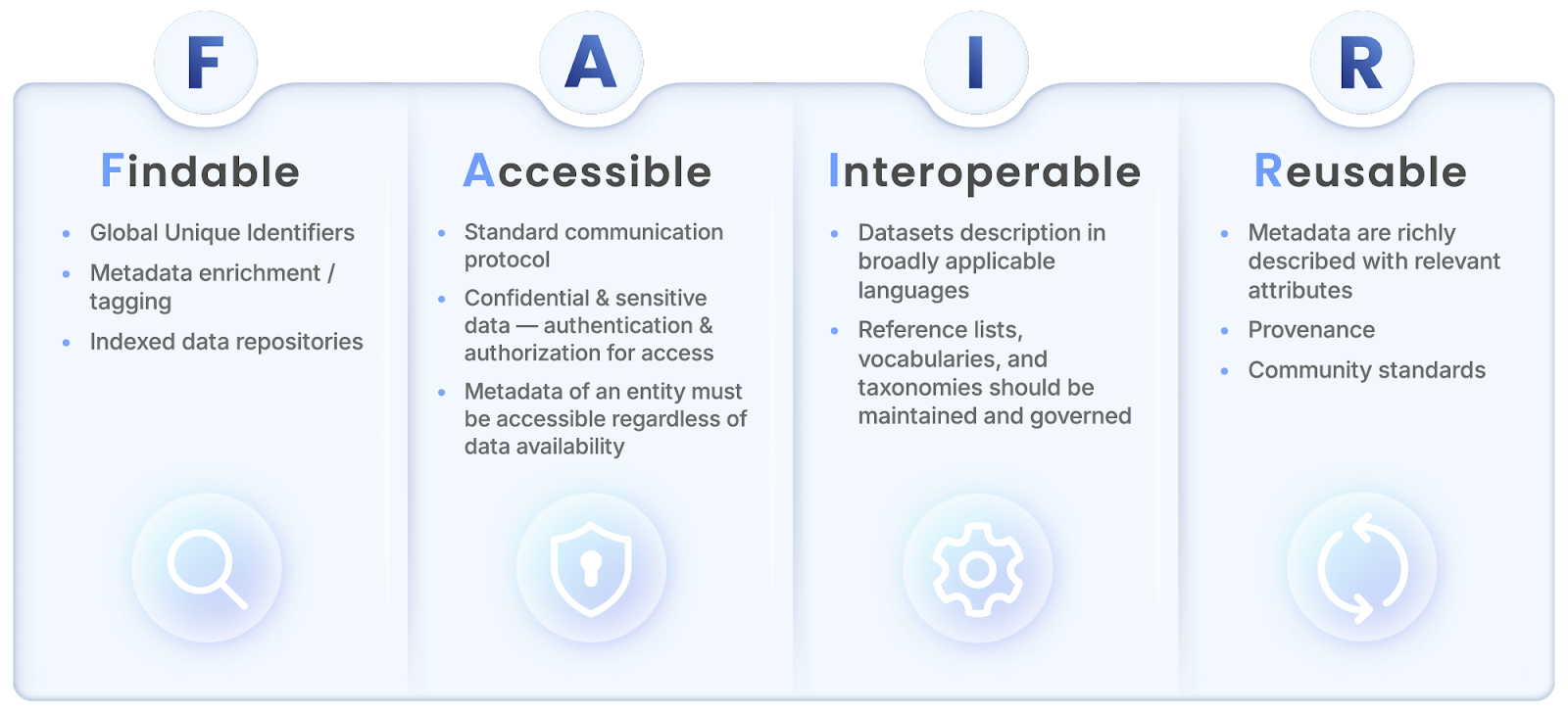
FAIR
The FAIR framework is largely aligned with catalog functionality such as Search & Discovery, re-usability, and increased focus on interoperability, which works well with building out an operations model for data governance. For more information on FAIR, check out: go-fair.org/fair-principles/.
These different approaches to running a data program — from different agencies, advocacy groups, and evangelists — all look at it differently, but in reality they all need a base set of software capabilities to make them work. It doesn't mean that a firm needs to buy all the software in each of these spaces, but understanding the capability and finding ways to deliver those capabilities cost-effectively is key for long-term success.
Software categories
This section breaks down each of these different areas across the ten core areas of this series.
People
Every data program runs on coordination. The tools in this category handle communication, documentation, and task tracking — the connective tissue that keeps data teams, stewards, and stakeholders aligned across projects and incidents.
Software capability
Description
Email
Traditional communication for long-form correspondence across teams and stakeholders.
Instant messaging
Brings together data coaches, teams, and individuals for real-time help and internal partnership.
Wiki
An older approach to centralizing information. Typically retired or replaced as data catalogs are introduced.
Catalogs
Brings together data dictionaries, business glossaries, policies, and other documentation for centralized data management.
Project management software
Manages and tracks data-related projects, task assignments, follow-ups, and issue and risk tracking.
Ticketing & support tools
Enables creating, managing, tracking, and closing individual requests. Common platforms include Jira, ServiceNow, and Zendesk.
Data Literacy
Data literacy tools ensure that knowledge doesn't stay locked inside subject matter experts. This category covers the software used to define shared terminology, transfer expertise across teams, and build the internal capability that makes a data program self-sustaining.
Software capability
Description
Business glossaries
A central location for collecting and providing access to common definitions of terms, acronyms, and other business terminology.
Knowledge transfer software
Moves documentation and institutional knowledge from one place to another. Distinct from data pipeline tools — this is a coordination and sharing capability, not a transformation one.
Training software
The range of tools used to train employees and external resources on new data capabilities, processes, and standards.
Instant messaging
Brings together data coaches, teams, and individuals for real-time help and ongoing internal partnership.
Data Quality
Data quality tools span detection, profiling, and remediation. The category ranges from platforms that identify issues at scale using automated rules and anomaly detection, to tools that clean and standardize data at the point of ingestion or transformation.
Software capability
Description
Data quality
A broad category covering issue identification, rule execution across quality dimensions, data deduplication, address validation, and transformation against reference data.
Data observability
Shows how data is being handled across pipelines, including quality issue identification, pipeline visualization, user activity monitoring, and cost/benefit analysis by data object.
Data profiling
Used by data engineers and stewards to accelerate development of data models and pipelines, and to understand the baseline characteristics of a dataset before setting quality rules.
Cleansing & standardization
Cleans and standardizes data to meet organizational requirements, often as an alternative to correcting issues in the originating system.
Reference data management
Supports standardization by managing the controlled vocabularies, code lists, and lookup values that other systems depend on for consistency.
Data Privacy
Privacy tooling covers the full lifecycle of personal data — from discovering where it lives, to managing individual consent, to fulfilling the access and deletion requests that regulations require. These capabilities don't operate independently; they depend on knowing what data exists and where it flows.
Software capability
Description
Sensitive data scanning
Automatically finds, identifies, and classifies sensitive information across an organization's data landscape.
Data mapping & inventory
Helps organizations understand what data they have, where it lives, how it moves, and who uses it — the prerequisite for any meaningful privacy program.
Consent & preference management
Collects, records, and enforces individuals' choices about how their personal data is used.
Privacy risk assessment (PIA)
Helps organizations identify, evaluate, and manage privacy risks associated with how they collect, use, store, and share personal data.
DSAR management
Handles the full workflow for data subject access requests — receiving, verifying, processing, and fulfilling individuals' rights under GDPR, CCPA/CPRA, LGPD, HIPAA, and similar regulations.
Data Security
Security tooling protects data at every layer — who can access it, what leaves the perimeter, and how fast a team can detect and respond when something goes wrong. GRC platforms sit at the intersection of security operations and regulatory accountability.
Software capability
Description
Identity, access, & authentication
Controls who can access systems and data, verifies their identities, and enforces least-privilege security across the environment.
Endpoint & device security
Protects the physical devices that connect to your network from malware, data breaches, and unauthorized access.
Threat intrusion software
Identifies, analyzes, and responds to unauthorized or malicious activity on networks, systems, and applications before it causes serious damage.
Security orchestration (SOAR)
Helps security teams automate repetitive tasks, orchestrate workflows across multiple tools, and respond quickly to threats.
Data loss prevention
Identifies, monitors, and protects sensitive data from unauthorized access, accidental leaks, or malicious exfiltration — whether that data is in use, in motion, or at rest.
GRC
Enables organizations to manage governance, assess and mitigate risks, and ensure compliance with laws, regulations, and internal policies in a unified platform.
DataOps
DataOps tooling covers the full pipeline lifecycle — moving data, transforming it, modeling it, validating it, and hosting it. The platforms in this category are where the actual engineering work happens, and where most data failures originate when instrumentation is absent.
Software capability
Description
Data transfer tools
Moves raw files from one location to another. A lower-end capability, distinct from data pipeline tools that transform data in transit.
Data pipeline tools
Advanced tools for moving, transforming, and preparing data for use. Common platforms include Airflow, dbt, and Fivetran.
File sharing tools
Enables access to data in its home location without moving it. Common platforms include AWS S3 and Azure Blob Storage.
Data modeling tools
Creates structured models for how data is stored in a database, defining data objects and the relationships between them.
Models
Includes data models, canonical models, process models, and data flow models — the structural blueprints that define how data is organized and moves through a system.
Data validation tools
Compares data at source and target, identifies discrepancies, and verifies that processing completed correctly — increasing confidence in pipeline output.
Data platforms
The infrastructure that hosts all data. Common platforms include Databricks, Snowflake, and Redshift, as well as traditional on-premise systems.
Compliance and oversight
Compliance tooling bridges policy and operations. Catalogs make policies findable and actionable. Observability platforms provide the audit trail that demonstrates those policies are being enforced — and surfaces anomalies when they're not.
Software capability
Description
Catalogs
Brings together data dictionaries, glossaries, data quality details, policies, and other documentation required to demonstrate governance in practice.
Data observability
Monitors, documents, and ensures the health, quality, and reliability of data pipelines and data assets — providing the visibility that compliance audits require.
Data Enablement
Data enablement tools make expertise accessible beyond the people who hold it. This category spans the platforms used to document processes, distribute knowledge, and train the broad population of data consumers who aren't on the core data team.
Software capability
Description
Email
Traditional tools for communicating in long form across teams and stakeholders.
Knowledge management tools
Platforms that enable organizations to collect, store, organize, and surface knowledge for employees, teams, or customers.
Training tools
Includes learning management systems (LMS) and related platforms for creating, delivering, and tracking training programs.
Process documentation tools
Captures, standardizes, and communicates business processes, making them easier to follow, audit, and automate.
Publishing tools
Enables teams to create, format, distribute, and manage documents for internal and external audiences.
Wiki capability
An older approach to centralizing content for broad internal distribution. Often phased out as more structured knowledge management platforms are adopted.
Data Consumption
Consumption tooling is where data becomes decisions. This category covers statistical analysis, business intelligence, and AI platforms — the layer that determines whether a well-built data stack actually produces value for the people who depend on it.
Software capability
Description
Statistical tools
Includes programming languages such as R and Python, specialized platforms like SAS, SPSS, and Stata, and open-source alternatives for statistical analysis and modeling.
BI (business intelligence) tools
Software applications that help organizations collect, analyze, visualize, and act on business data to support informed decision-making.
AI tools
Platforms that use artificial intelligence and machine learning to analyze data, surface patterns, and generate actionable insights automatically or semi-automatically.
Role of AI trust in data architecture
Architecture is critical for AI trust. To achieve AI trust, firms need to monitor AI tools in lock-step, understand what tools are being used, and educate staff on the approach and policies for introducing new AI tools.
Firms also need to find tools that can detect unknown use of AI, verify they are being used correctly, and educate all staff in a way that HR, data security, data privacy, and other teams can trust.
Only with a handle on the other AI tools being used, and awareness and oversight of these AI capabilities, can a firm have AI trust.
Bigeye's role in data architecture
Bigeye offers a range of capabilities, including data lineage, data quality, and issue resolution management. Over time firms will encounter consolidation of tools, and the expansion of Bigeye into lineage is a great example of this type of evolution.
Summary
Data programs are successful when they have a solid approach to data literacy, data quality, data privacy, data security, DataOps, data enablement, data consumption, and policy management. All of these capabilities require a solid focus on people, and the right tools in the right architecture for success.
Explore the Series
Every great data program is built from the ground up.
The House of Data breaks down the ten pillars of a mature, trustworthy data organization. Click any section to explore that paper.
Specific datasets in great detail. Looking for outliers, duplication, and other—sometimes subtle—issues that could affect their analysis or machine learning models.
Freshness monitoringCompleteness monitoringDuplicate detectionOutlier detectionDistribution shift detectionDimensional slicing and dicing
Analytics engineers
Rapidly testing the changes they’re making within the data model. Move fast and not break things—without spending hours writing tons of pipeline tests.
Lineage monitoringETL blue/green testing
Business intelligence analysts
The business impact of data. Understand where they should spend their time digging in, and when they have a red herring caused by a data pipeline problem.
Integration with analytics toolsAnomaly detectionCustom business metricsDimensional slicing and dicing
Other stakeholders
Data reliability. Customers and stakeholders don’t want data issues to bog them down, delay deadlines, or provide inaccurate information.
Integration with analytics toolsReporting and insights
about the author
Jim Barker
Principal, Data Strategy
Jim Barker is a lifelong data practitioner, industry thought leader, and passionate advocate for treating data as a strategic asset. With more than four decades of experience spanning data quality, governance, warehousing, migration, and architecture, Jim brings a rare blend of hands-on expertise and executive perspective to the evolving data landscape.
Jim’s journey in data began at just 14 years old. Since then, he has held leadership roles across organizations including Honeywell, Informatica, Thomson Reuters, Winshuttle (Precisely), Alation, and nCloud Integrators, contributing to advancements in data governance, migration methodologies, and enterprise data strategies. His work has included building global data quality programs, developing scalable governance frameworks, and driving innovation recognized across the industry.
His research and writing focus on lean data management, governance strategies, and the intersection of AI, data quality, and enterprise value creation.
Now at Bigeye, Jim is energized by the company’s vision for AI Trust and its role in shaping the future of data. He continues to share his perspectives through writing and speaking, aiming to elevate the conversation around data, cut through industry noise, and help organizations do data the right way.
Outside of work, Jim enjoys spending time with his family, often around bikes, fishing, horses or robots. Much of Jim’s professional success has been influenced by activities with his kids prior to their graduating from college. In the past he was quite involved in coaching basketball and coaching,where many of the same lessons about teamwork, discipline, and leadership apply.
As Jim puts it: “Data matters.”
about the author
about the author
Jim Barker is a lifelong data practitioner, industry thought leader, and passionate advocate for treating data as a strategic asset. With more than four decades of experience spanning data quality, governance, warehousing, migration, and architecture, Jim brings a rare blend of hands-on expertise and executive perspective to the evolving data landscape.
Jim’s journey in data began at just 14 years old. Since then, he has held leadership roles across organizations including Honeywell, Informatica, Thomson Reuters, Winshuttle (Precisely), Alation, and nCloud Integrators, contributing to advancements in data governance, migration methodologies, and enterprise data strategies. His work has included building global data quality programs, developing scalable governance frameworks, and driving innovation recognized across the industry.
His research and writing focus on lean data management, governance strategies, and the intersection of AI, data quality, and enterprise value creation.
Now at Bigeye, Jim is energized by the company’s vision for AI Trust and its role in shaping the future of data. He continues to share his perspectives through writing and speaking, aiming to elevate the conversation around data, cut through industry noise, and help organizations do data the right way.
Outside of work, Jim enjoys spending time with his family, often around bikes, fishing, horses or robots. Much of Jim’s professional success has been influenced by activities with his kids prior to their graduating from college. In the past he was quite involved in coaching basketball and coaching,where many of the same lessons about teamwork, discipline, and leadership apply.
As Jim puts it: “Data matters.”
Get the Best of Data Leadership
Subscribe to the Data Leaders Digest for exclusive content on data reliability, observability, and leadership from top industry experts.
Want the practical playbook?
Join us on April 16 for The AI Trust Summit, a one-day virtual summit focused on the production blockers that keep enterprise AI from scaling: reliability, permissions, auditability, data readiness, and governance.
Get Data Insights Delivered
Join hundreds of data professionals who subscribe to the Data Leaders Digest for actionable insights and expert advice.
.png)
.png)


.png)
.png)

.png)