
Get the Best of Data Leadership
Stay Informed
Get Data Insights Delivered
For years, enterprise data governance was designed for people.
Access happened through defined workflows. Queries came from known users. Policies were applied at the system level. Controls reflected predictable patterns of use.
That model assumed data access was deliberate and human-driven.
AI changes that.
Agents do not access data the way people do. They operate continuously, querying multiple systems at once. They move across operational databases and warehouses in seconds. They combine datasets dynamically. Once deployed, they act at machine speed.
As enterprises connect multiple AI platforms to multiple data sources, the surface area of data access expands rapidly.
Data that was once accessed by a small group of analysts can now influence automated decisions and agent responses. Regulated fields can propagate across domains before teams realize it. Sensitive data no longer stays confined to a source system; it becomes part of AI-enabled workflows.
Enterprises are being asked to scale AI responsibly without always knowing what data their AI systems are using, whether that data is reliable, or whether it should be accessed at all. Solving that problem requires more than monitoring pipelines. It requires visibility into data access, and the means to control that access.
The Bigeye AI Trust Platform
The Bigeye AI Trust Platform brings data reliability, sensitivity, governance, and AI access into one system. Built as a layered architecture, it does not treat these capabilities as separate tools, but connects them so the status of your data directly informs how AI is allowed to use it.
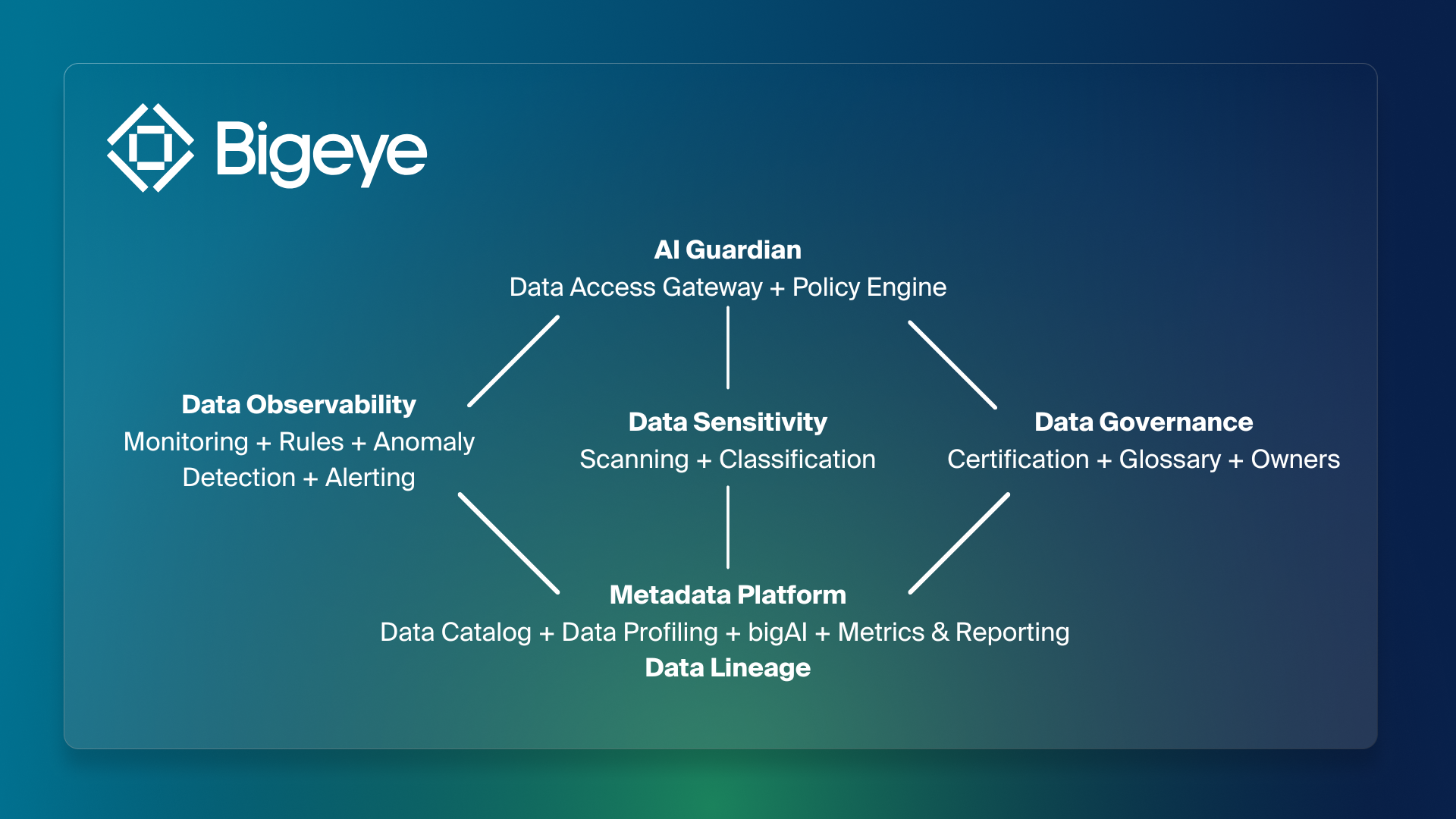
At the foundation is Metadata Management, a continuously updated map of the enterprise data estate. It catalogs schemas, tables, columns, jobs, reports, and domains across modern and legacy systems. It profiles datasets, assigns ownership, enables tagging of critical data elements, and provides unified search across the stack.
This is supported by end-to-end, column-level lineage. Lineage shows where data originates, how it is transformed, and where it flows across warehouses, ETL jobs, BI tools, and downstream systems. That context makes it possible to understand not just what data exists, but how it is being used.
On top of that foundation sit three domains: data observability, data sensitivity and data governance.
Data Observability monitors reliability. It adapts as new tables, columns, and pipelines appear. It detects anomalies in freshness, volume, distribution, and other indicators of health. Alerts are lineage-aware, showing where issues started and what downstream assets are affected.
In AI environments, this matters because agents can continue operating while quietly consuming degraded data. Reliability must be measured continuously, not assumed.
Data Governance defines accountability. Ownership can be assigned at the schema, table, or column level. Domains organize assets by team or function. Certification clarifies which datasets are approved for specific uses. Because governance is connected to lineage and monitoring, policies reflect how data actually behaves across systems.
Data Sensitivity identifies regulated and high-impact data classes across structured sources. It continuously evaluates for PII, PHI, PCI, PFI, and other sensitive categories using pre-built and configurable classifiers backed by AI-assisted detection. Incremental and ongoing scans evaluate new and modified data so coverage keeps pace with change while controlling cost.
These domains work together to supply the signals that inform AI behavior.
Above them sits AI Governance, implemented by Bigeye’s AI Guardian and supported by the AI Data Gateway and Policy Engine. AI systems access enterprise data through a governed control point rather than unmanaged connections. At that control point, reliability, sensitivity, and certification status are evaluated before data is used.
AI Guardian is the runtime enforcement layer for this architecture. When an AI system issues a request, Guardian evaluates it against trust signals from Data Observability, Data Sensitivity, and Data Governance before returning results. That evaluation can run in monitoring mode for visibility, in advising mode to guide agents toward better datasets, or in strict steering mode where non-compliant access is blocked.
The Role of Sensitive Data Scanning
Within the AI Trust Platform, Sensitive Data Scanning is the piece that turns knowledge of sensitive data into the signals AI Governance uses to enforce control.
The platform-level Data Sensitivity capabilities describe how regulated fields are discovered, classified, and tied to lineage and catalog context. Sensitive Data Scanning takes that foundation and makes it usable in real time by the teams and systems that need it most.
The shift is simple but important: sensitive data is no longer just documented. It becomes part of how decisions are made.
In traditional environments, discovery results lived in static reports and spreadsheets. They were useful for audits and one-off reviews, but they rarely stayed in sync with how data moved through pipelines or how it was reused by different teams. By the time an issue surfaced, the underlying exposure was often weeks or months old.
In an AI-driven estate, that model breaks down quickly.
Agents and AI applications inherit whatever is happening in the data estate. If sensitive fields drift into new tables, domains, or aggregates, agents will follow. Without live sensitivity context, requests can look harmless on the surface while pulling in regulated information behind the scenes.
Sensitive Data Scanning closes that gap by keeping sensitivity attached to the data as it moves and making those classifications available at the moment of access.
When schemas change, classifications update with them. When sensitive data appears in an unexpected downstream system, lineage shows where it originated, how it moved through the stack, and which downstream assets are affected. When a dataset feeds an AI workflow, its sensitivity status is already known and available to the controls sitting in front of it.
That is where enforcement comes in.
Sensitive Data Scanning feeds these signals into AI Governance through Bigeye’s AI Guardian layer. When an AI system requests data, Guardian can see which fields are sensitive, what class they fall into, and how they should be handled under current policy. Depending on those rules, access can proceed, be redirected to safer datasets, or be blocked outright.
If a dataset that was previously safe begins to include regulated fields, its sensitivity status changes how AI is allowed to use it. If sensitive data shows up in a domain where it does not belong, teams have both the context to investigate and the ability to prevent agents from touching it. The same signals that support audits and privacy workflows also drive real-time decisions about AI access.
Sensitive Data Scanning, in this role, is not just about finding sensitive data. It supplies the live sensitivity signals that allow governance, security, and AI teams to move from knowing where regulated data is, to controlling how it is used.
What This Enables
For CISOs and their teams, this means sensitive data is no longer a static inventory. It is a continuously updated view of where regulated information lives, how it moves, and which systems are exposed. Audit preparation becomes a matter of showing evidence, not rebuilding it from scratch.
For Chief AI Officers and AI platform leaders, it answers a question that increasingly decides whether AI projects move forward: are our agents touching data they shouldn’t? As AI initiatives grow, leaders can see which datasets agents are drawing from, whether those datasets contain sensitive fields, and how that exposure is being handled.
Both roles gain confidence that AI systems are operating on data that is reliable, appropriate, and visible.
Now Available
While AI adoption accelerates, responsible access to enterprise data cannot rely on periodic review. It requires a system that keeps reliability, sensitivity, and governance aligned in real time. With this release, enterprises can move beyond static tools to a continuous view of sensitive data tied directly to lineage, observability, and AI governance.
Sensitive Data Scanning brings that capability into the AI Trust Platform.
Sensitive Data Scanning is now available in its initial release within the Bigeye AI Trust Platform. Existing Bigeye customers can contact their Customer Success Engineer to add it to their deployment. If you’re evaluating how to control sensitive data in AI workflows, request a demo to see how the platform works end to end.
Monitoring
Schema change detection
Lineage monitoring

Skailar Hage
.png)
Adrian Vidal


