How Lineage Works: A Bigeye Product Walkthrough
Data lineage can be a challenge in complex enterprise stacks. This article walks through how Bigeye captures lineage automatically across modern and legacy systems and how teams use it for impact analysis, monitoring strategy, and faster incident investigation.


Get the Best of Data Leadership
Stay Informed
Get Data Insights Delivered
Data lineage sounds straightforward in theory. You track where data originates, how it changes across transformations, and where it is ultimately consumed.
In practice, it's a lot more complicated than that. Modern data environments span warehouses, ETL platforms, transformation layers, BI tools, and often a long tail of legacy systems. Each of these systems introduces its own metadata and transformation logic, and those definitions rarely align across tools.
Most enterprises already have some form of lineage today. Warehouses expose lineage internally, BI tools track query dependencies, and transformation frameworks can visualize model relationships. The challenge is that these lineage views typically exist in isolation. Each system only understands the portion of the data flow it controls.
This creates fragmented lineage across the stack. Teams can see lineage within a single platform, but they cannot easily trace how data moves across systems, from ingestion through transformations and into downstream business assets.
That lack of trust becomes most visible during incidents. Impact analysis requires understanding which downstream assets depend on a dataset, table, or column. Root cause analysis requires tracing issues across every system the data passed through.
When lineage is incomplete or outdated, teams fall back on manual investigation and tribal knowledge. Resolution slows down and operational risk increases.
For lineage to remain useful in enterprise environments, it must be automated, cross-source, and continuously aligned with live data behavior.
Bigeye’s Approach to Data Lineage
Bigeye’s data lineage is designed to reflect how data actually moves through enterprise data environments in production. This includes modern cloud platforms, transformation frameworks, and legacy systems.
Rather than treating lineage as a standalone artifact or diagram, Bigeye treats lineage as active metadata that powers how teams understand, monitor, and investigate their data systems.
At its core, Bigeye lineage helps teams answer three practical questions:
- Where did this data come from?
- What happened to it along the way?
- Who and what depends on it today?
Lineage is deeply integrated into the Bigeye data observability platform. The same metadata foundation that powers monitoring, anomaly detection, issue triage, and sensitive data discovery also powers lineage.
Because these capabilities share the same underlying metadata model, lineage is not simply visual context. It actively informs how issues are investigated, how alerts are prioritized, and how anomalies are connected to upstream root causes.
A key difference in Bigeye’s approach is breadth of integration. Instead of focusing on lineage within a single platform, Bigeye integrates across the systems where enterprise data actually moves.
This includes cloud warehouses, transformation frameworks, ETL platforms, BI tools, and legacy databases. By capturing metadata across these systems, Bigeye constructs lineage that spans the full data lifecycle rather than a single layer of the stack.
End-to-end lineage in Bigeye spans the full data estate:
- Data sources such as warehouses, databases, and ingestion systems
- Transformation layers and pipeline logic
- Downstream consumers including reports, dashboards, models, and external systems
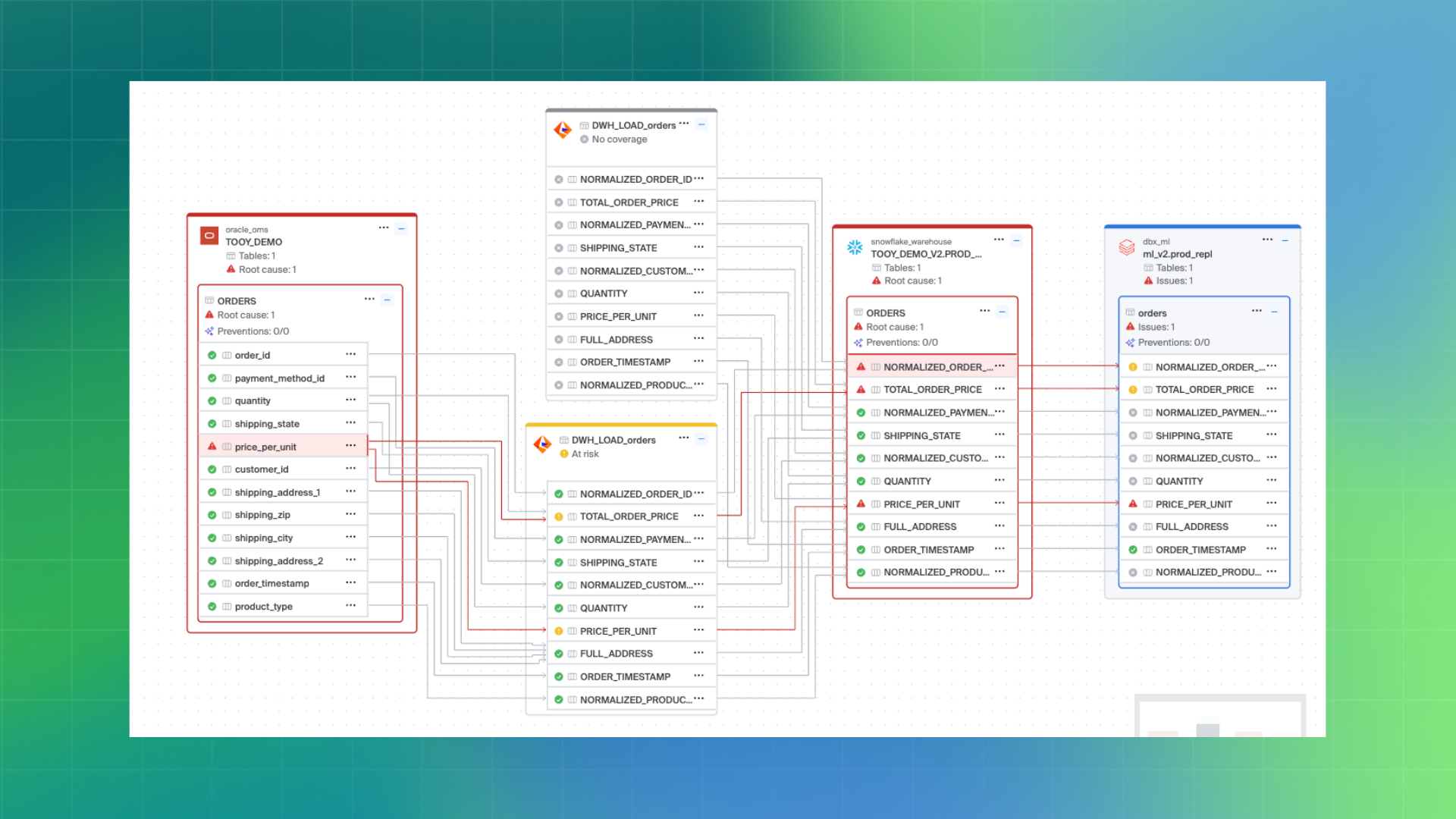
This allows teams to follow data as it moves through the enterprise ecosystem, across systems and across transformation boundaries.
Unlike traditional lineage tools that generate static diagrams, Bigeye treats lineage as continuously updating metadata. As schemas change, pipelines evolve, or new transformations are introduced, lineage updates automatically.
How lineage is captured and maintained
For lineage to be reliable, it must be collected and kept continuously up to date. Bigeye captures lineage directly from the systems where data transformations are happening.
Bigeye integrates with enterprise data sources across the stack, including warehouses, ETL platforms, transformation frameworks, and BI tools. Instead of requiring teams to document lineage manually, Bigeye extracts lineage from the metadata and transformation logic that already exists within these systems.
This approach ensures lineage reflects how pipelines actually run in production rather than relying on manually maintained documentation.
At the core of lineage collection are specialized parsers that interpret how different platforms define data movement and transformation. These parsers analyze SQL queries, transformation logic, job definitions, and query metadata to determine how data is read, transformed, and written.
By extracting lineage directly from execution logic, Bigeye avoids guesswork. Lineage relationships are derived from real system behavior rather than inferred connections.
Enterprise lineage rarely exists within a single system. Data flows from source databases into warehouses, through transformation layers, and into downstream data consumers via BI platforms.
Bigeye correlates metadata across these systems and stitches them together into a single unified lineage graph. This cross-source stitching enables true end-to-end lineage across modern and legacy environments.
Column-level lineage plays a critical role in this model. At a practical level, column-level lineage answers a simple but essential question: Where did this field originate?
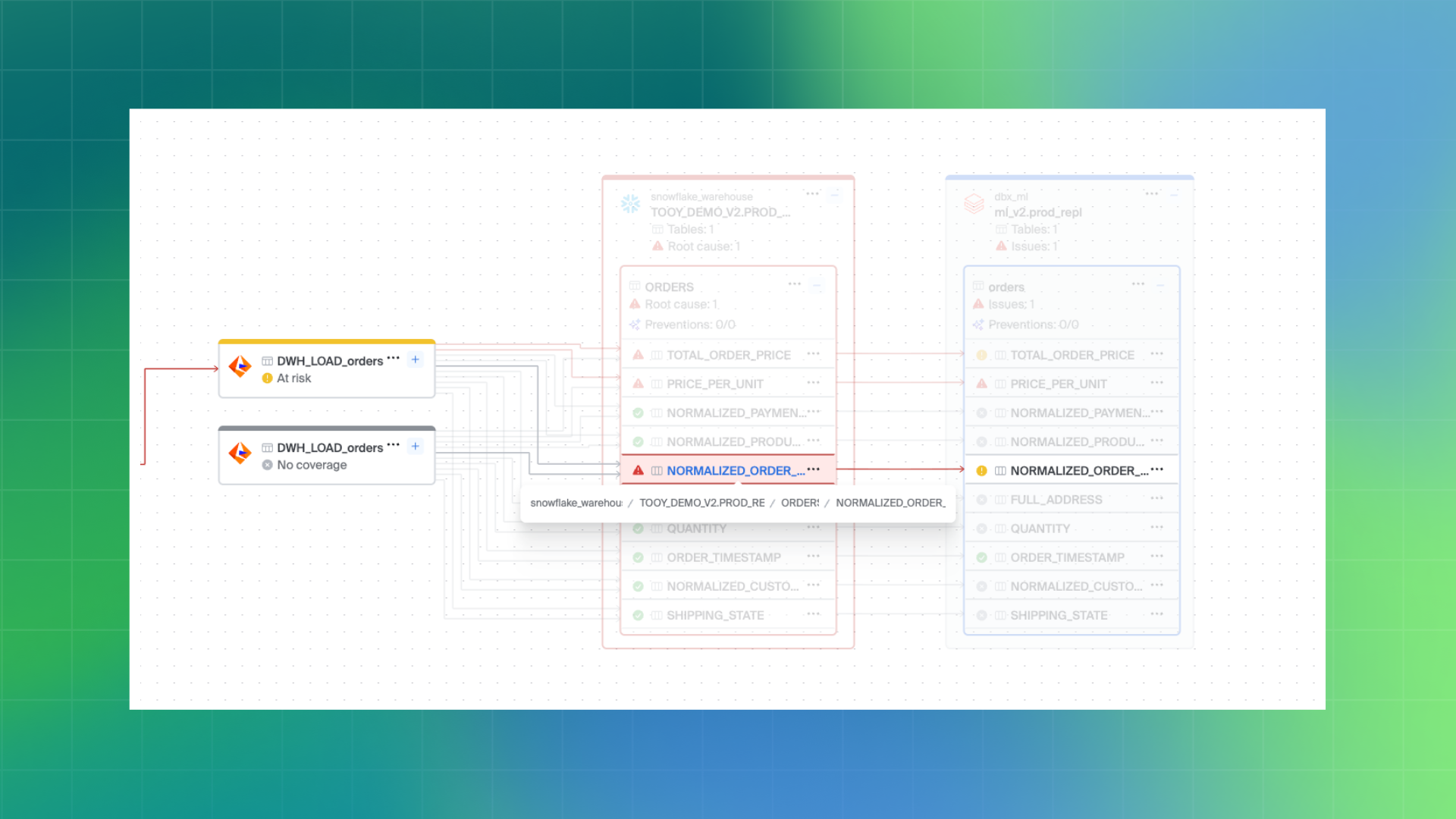
Bigeye tracks how individual columns are created, joined, filtered, aggregated, or derived across pipelines. This makes it possible to trace a dashboard metric back to its raw source data, even when that metric results from multiple transformation steps.
In practice, this dramatically simplifies investigations. Teams can move directly from a broken metric or unexpected value to the specific transformation or upstream dataset responsible.
(Curious how we balance visibility and privacy when working with your data? Our Field CTO breaks it all down here.)
Understanding Lineage in Bigeye
Within Bigeye, lineage is presented as a navigable graph of data relationships that shows how assets connect across sources, transformations, and downstream consumers.
Each node represents a data asset such as a table, column, pipeline job, or dashboard. Edges between nodes represent how data flows between them.
Rather than overwhelming users with the entire ecosystem at once, the lineage interface allows users to expand or collapse portions of the graph and focus on the relevant portion of the system.
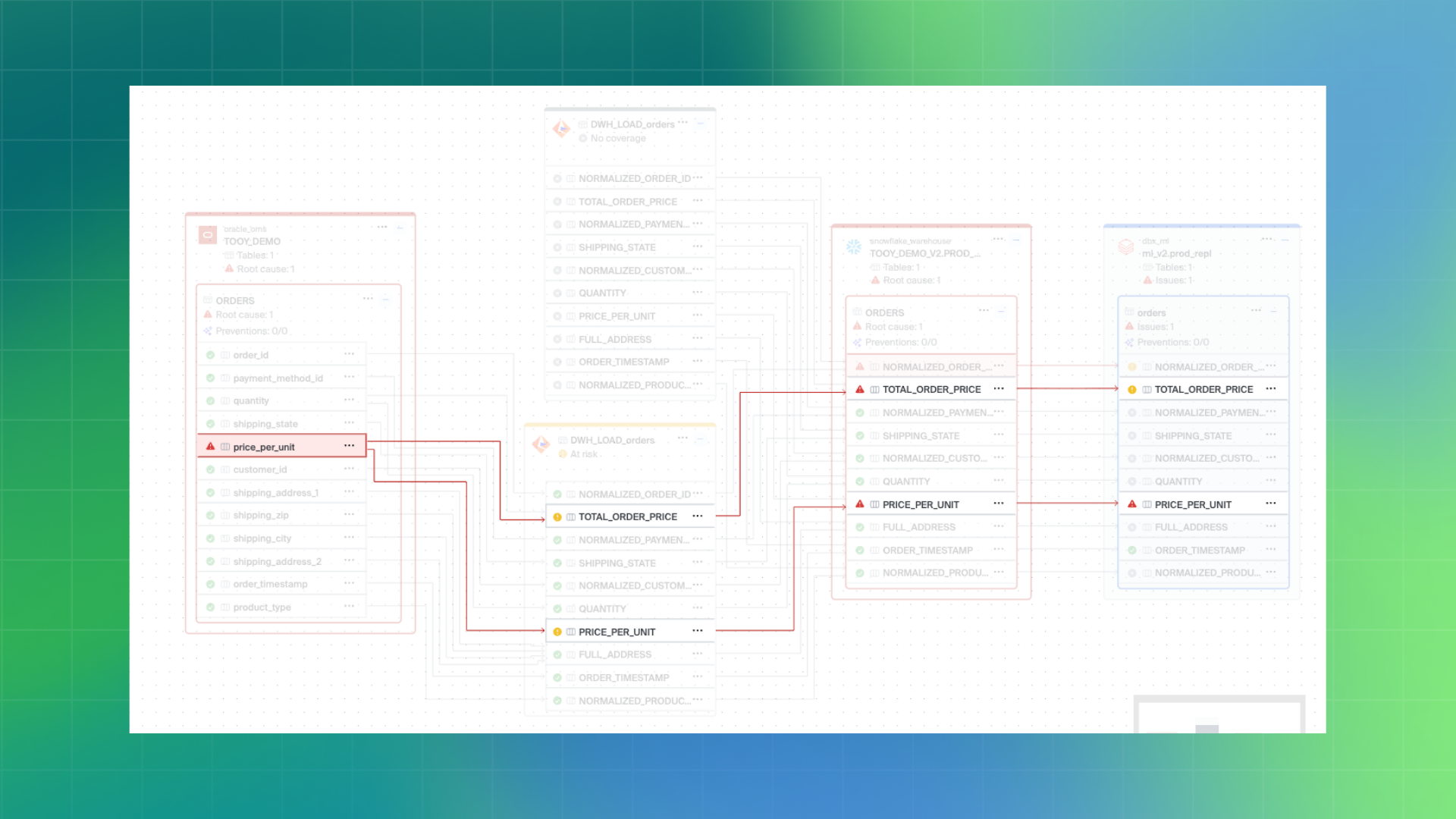
Teams typically reason about lineage in two directions: upstream and downstream.
Upstream exploration helps answer questions like where data originated, which transformations produced it, and which source systems it depends on. Downstream exploration answers the inverse: which dashboards, models, or applications rely on a given dataset.
Lineage views also include transformation context and job metadata. Teams can see how data was joined, filtered, aggregated, or derived, as well as which pipelines executed those transformations.
Bigeye also allows users to explore lineage at multiple scopes depending on the question being investigated. Teams can zoom into column-level lineage to trace individual fields, step back to table-level lineage to understand dataset dependencies, or view schema-level relationships to understand broader system structure.
This flexibility allows teams to investigate issues without being overwhelmed by unnecessary detail.
In practice, teams use lineage to quickly answer operational questions:
- Why did this metric change?
- What breaks if we modify this pipeline?
- Where should we investigate this alert?
- Which downstream teams might be affected?
By combining a navigable lineage graph, transformation context, and flexible scope, Bigeye turns lineage into a practical investigation tool rather than a static visualization.
Using Lineage for Impact Analysis
Impact analysis often begins with a single problem: a dataset with unexpected values, a delayed pipeline, or an anomaly alert.
From that starting point, lineage immediately places the issue in context. Teams can see where the problem sits within the broader data flow and how it connects to upstream sources and downstream consumers.
One of the most difficult parts of incident response is understanding the blast radius of a failure. A small upstream issue can propagate across dozens of downstream assets—or it may affect nothing at all.
Lineage makes this visible. Teams can see every downstream table, model, dashboard, or system that depends on the affected dataset.
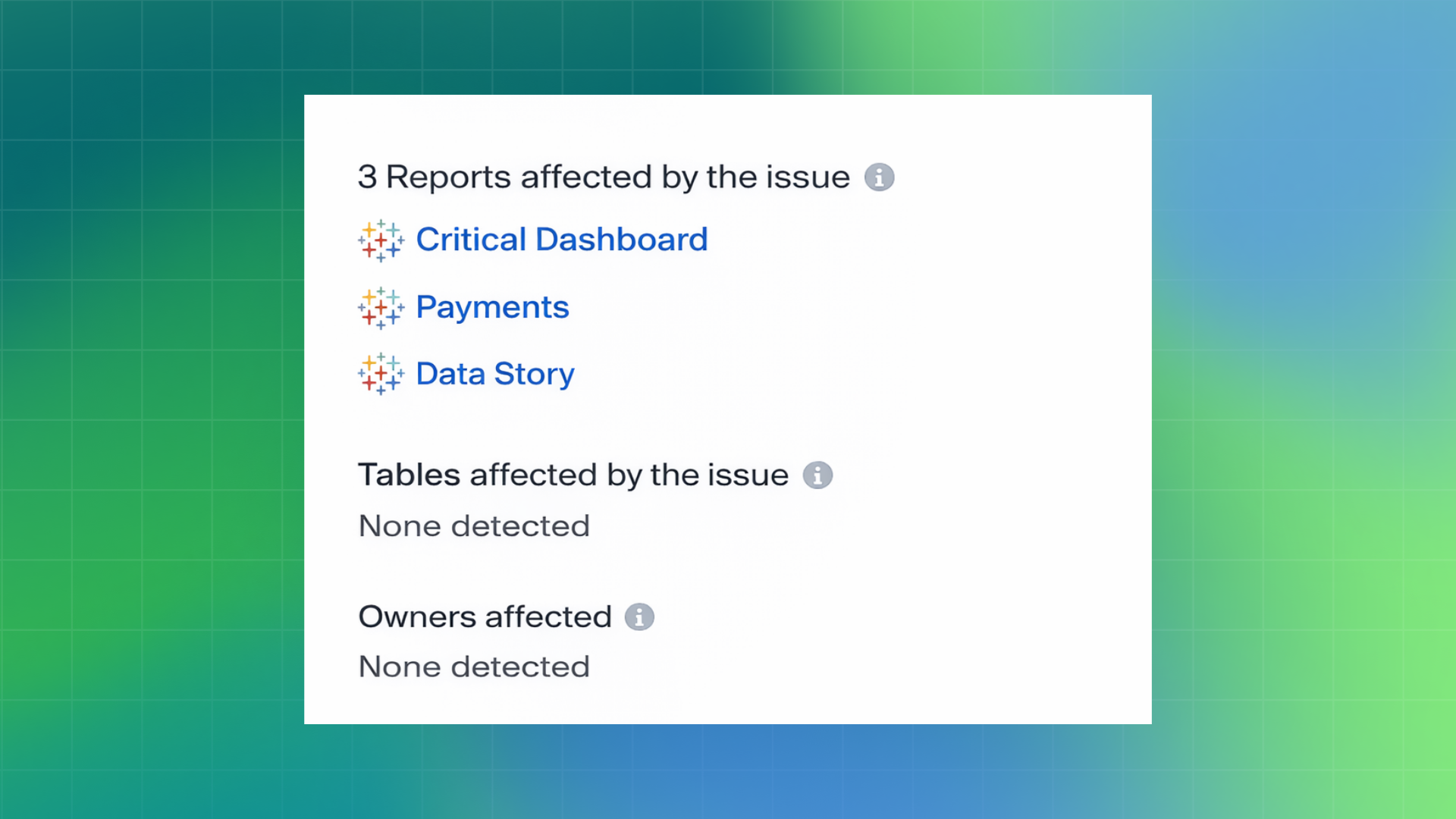
This visibility also helps teams prioritize their response. Not all alerts require the same urgency. Some incidents affect executive dashboards or customer-facing reports, while others may impact low-usage internal assets.
By tying alerts to downstream impact, lineage helps teams distinguish between high-impact incidents and low-impact noise.
Clear lineage also improves communication during incidents. When teams understand the full scope of an issue, they can confidently explain what is affected, what is not, and what actions are being taken.
Lineage Across Modern and Legacy Systems
Enterprise data ecosystems rarely consist solely of modern tools. Most organizations operate across a mix of cloud platforms, on-prem systems, and legacy technologies accumulated over many years.
Bigeye’s lineage is designed for these hybrid environments. Whether data originates in a cloud warehouse, legacy database, or moves between both, lineage captures how data flows across those boundaries.
This capability is particularly important for enterprises in regulated industries where legacy platforms remain deeply embedded in business operations.
Many lineage solutions break down when legacy systems enter the picture. But critical datasets in industries like financial services, healthcare, and retail often originate in those systems.
Bigeye extends lineage all the way back to those original sources, ensuring teams can trace data flows from legacy environments through modern analytics and BI layers.
Lineage as a Foundation for Data Trust
Once lineage is accurate, automated, and integrated into operational workflows, it stops being something teams consult occasionally and becomes something they rely on every day.
Engineers use lineage to assess change risk before modifying pipelines. Analysts use it to validate how metrics are produced. Platform teams use it to investigate incidents and understand downstream exposure.
What begins as visibility into data relationships ultimately becomes a shared understanding of how the data ecosystem operates.
Lineage connects systems, teams, and decisions. It replaces unclear dependencies with explicit relationships and gives teams the context they need to move faster and investigate issues with confidence.
When combined with monitoring, observability, and sensitive data discovery, lineage becomes a critical foundation for building trust in enterprise data systems.
Monitoring
Schema change detection
Lineage monitoring
Skailar Hage
.png)
Adrian Vidal


