
Get the Best of Data Leadership
Stay Informed
Get Data Insights Delivered
Enterprises are expected to keep sensitive information compliant, auditable, and secure at all times. To meet these expectations, many organizations turn to sensitive data scanning tools- solutions designed to automatically inspect data across warehouses, lakes, and pipelines to identify information such as PII, PHI, financial data, and regulated identifiers.
In practice, however, many of today’s solutions fall short in critical ways. Data lineage support is often minimal or nonexistent, meaning that even when sensitive data is detected, teams lack an end-to-end view of where it originated, how it moved through the data stack, and which downstream systems are impacted. At the same time, these tools are frequently expensive and offer limited cost-control capabilities, such as incremental scanning. As a result, organizations are forced to repeatedly rescan massive datasets, driving up compute costs and operational overhead.
When sensitive data issues inevitably arise, data teams are under intense pressure to act quickly, containing risk before it turns into financial loss or reputational damage. Yet sensitive data is typically scattered across dozens of systems, and teams lack the visibility needed to understand where it lives, how it got there, or how the business may be using it.
As teams scramble to investigate manually, they’re often left asking the same questions:
- Where did this data come from?
- How long has it been exposed?
- What caused the issue in the first place?
Bigeye’s Sensitive Data Scanning module was built to answer these questions. It enables enterprise data teams to discover and classify sensitive data across their entire data ecosystem, from modern platforms to legacy databases, while enriching findings with context-rich lineage. With continuous visibility and high-accuracy precision and recall, teams can quickly understand where sensitive data originated, how long it has been exposed, and exactly how it moved through the data stack.
Understanding Sensitive Data Scan Types
Bigeye’s Sensitive Data Scanning module gives data teams precise control over how, when, and where sensitive data is scanned. Instead of forcing a one-size-fits-all approach, teams can select exactly which data sources, schemas, tables, or objects should be included in each scan.
Once data sources are selected, teams can choose the scan type that best fits the use case, such as full, incremental, auto, or sampled scans. Each scan type is designed to serve a different purpose, allowing teams to apply the right level of scrutiny at the right time. This flexibility makes it possible to scan different datasets on different schedules while maintaining tighter control over performance and cost.
Bigeye includes dozens of out-of-the-box sensitive data classifiers that work seamlessly across all scan types. Common sensitive data—such as credit card numbers, bank account numbers, and other PII, PHI, PCI, and PFI—can be automatically identified and classified, while still allowing teams to fine-tune detection rules based on their specific requirements.
So what are the different scan job types, and when should each be used?
Let’s break down the most common options—and the pros and cons of each.
Full, Incremental, Auto, and Sampled Scans
Bigeye supports four types of sensitive data scan jobs:
- Full
- Incremental
- Auto
- Sampled Scans
Each scan type is designed to address different discovery, monitoring, and cost considerations.
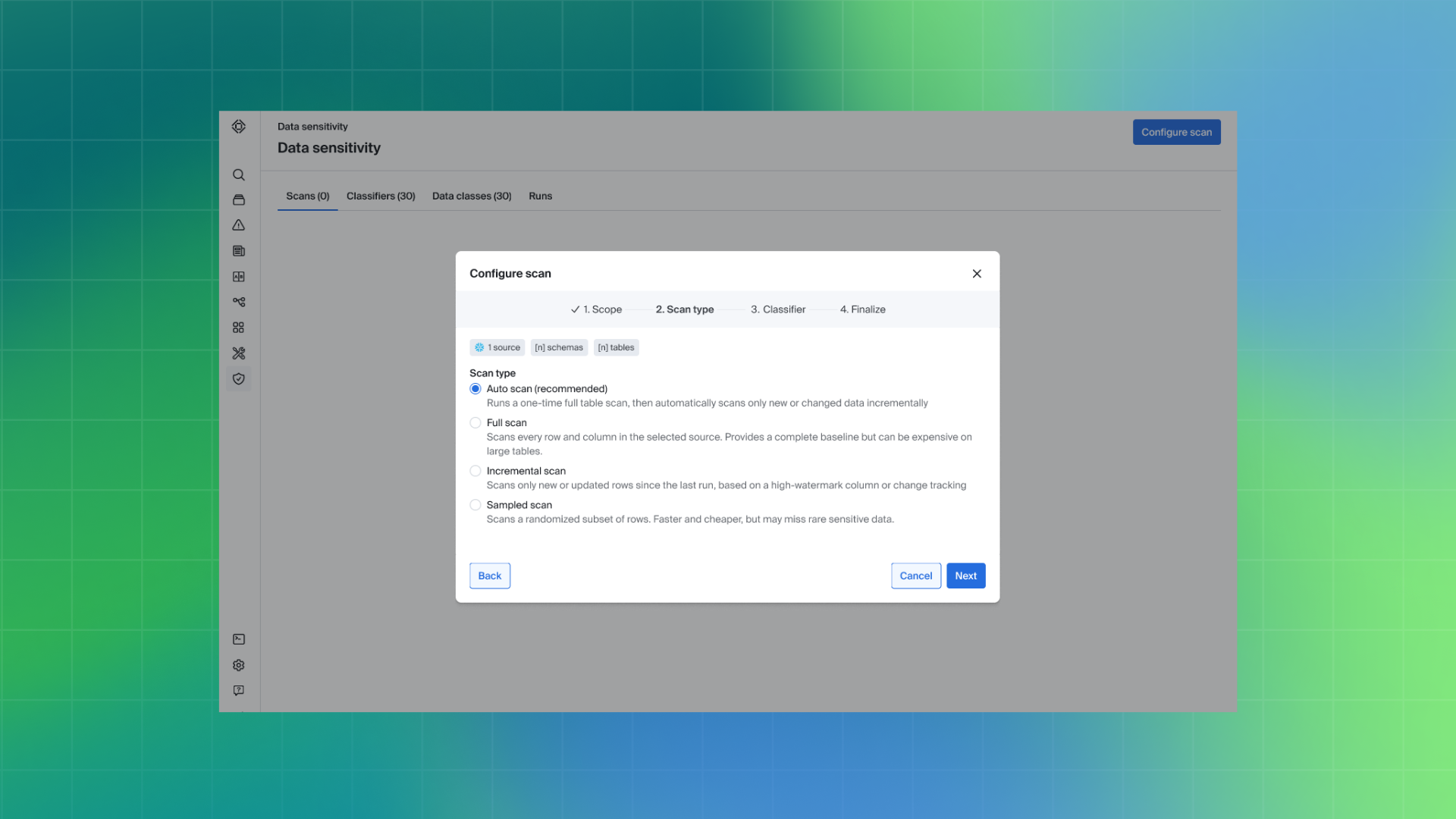
Full scans analyze all selected data sources and objects end to end, producing a complete inventory of identified sensitive data. This scan type provides the most comprehensive coverage and is commonly used for initial discovery or compliance-driven assessments. Because full scans process all data, they are the most time- and compute-intensive option.
Incremental scans evaluate only the data that has changed since the last successful scan, such as newly created or updated files, tables, or columns. This approach keeps sensitive data findings current without the cost and runtime overhead of reprocessing unchanged data. Incremental scanning is especially valuable for maintaining consistent coverage while controlling costs and reducing operational burden.
Auto scans combine full and incremental scanning into a single workflow. Teams run an initial full scan to establish a baseline, after which Bigeye automatically scans newly changed data on an ongoing basis. This option is well suited for teams that want continuous visibility with minimal manual intervention.
Sampled scans analyze a subset of data rather than entire datasets. This scan type allows teams to gain directional insight into where sensitive data may exist within large tables while limiting compute usage. Sampled scans are often used for exploratory analysis or early-stage discovery.
How Bigeye Detects Sensitive Data
When a scan job runs, Bigeye applies a combination of built-in classifiers and machine learning to identify and classify sensitive data in the selected sources.
Sensitive data detection relies on machine learning models that are evaluated using both precision and recall. Precision measures how often identified results are correct, while recall measures how much relevant sensitive data is successfully detected. Bigeye is designed to balance both metrics, reducing the likelihood of missed sensitive data as well as incorrect classifications.
This balance is important because focusing on precision alone can lead to inconsistent results. Without strong recall, sensitive data may go undetected, while overcorrection can increase false positives. Both scenarios create downstream challenges for data, security, and compliance teams, including increased investigation effort, higher operational costs, and delayed response times.
By combining rule-based classifiers with machine learning and evaluating results across both precision and recall, Bigeye aims to provide reliable detection without excessive noise.
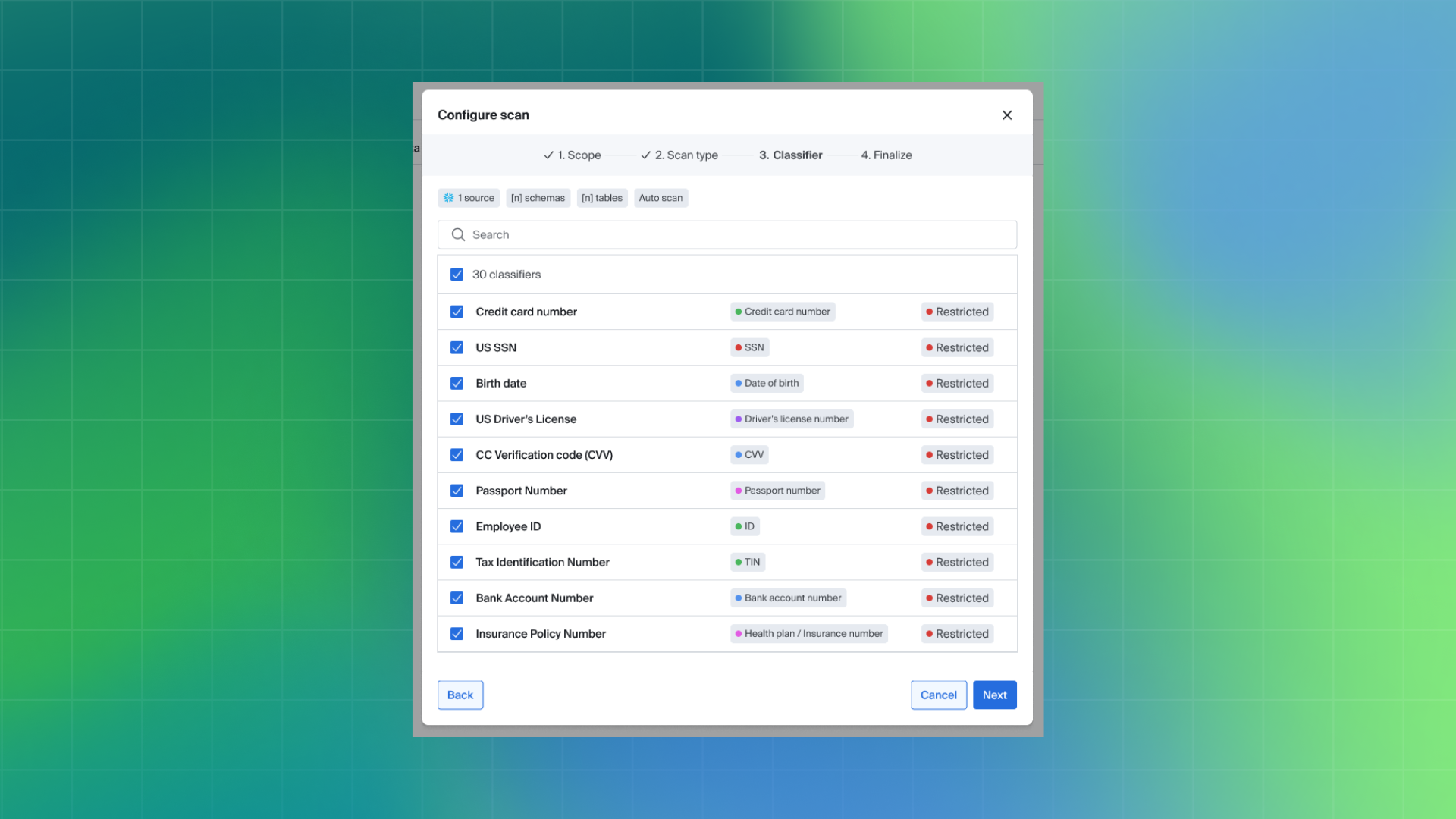
Reviewing Scan Findings
After a scan completes, users can view a consolidated summary of all scanned tables and see which data has been classified as sensitive across the selected data sources. This aggregated view makes it easier to understand where sensitive data exists and which assets require further review.
Scan results are grouped and presented in a way that allows users to quickly identify the types of sensitive data detected, without having to inspect individual tables one by one. Findings are based on the same classification logic used during scanning, helping ensure consistency between detection and reporting.
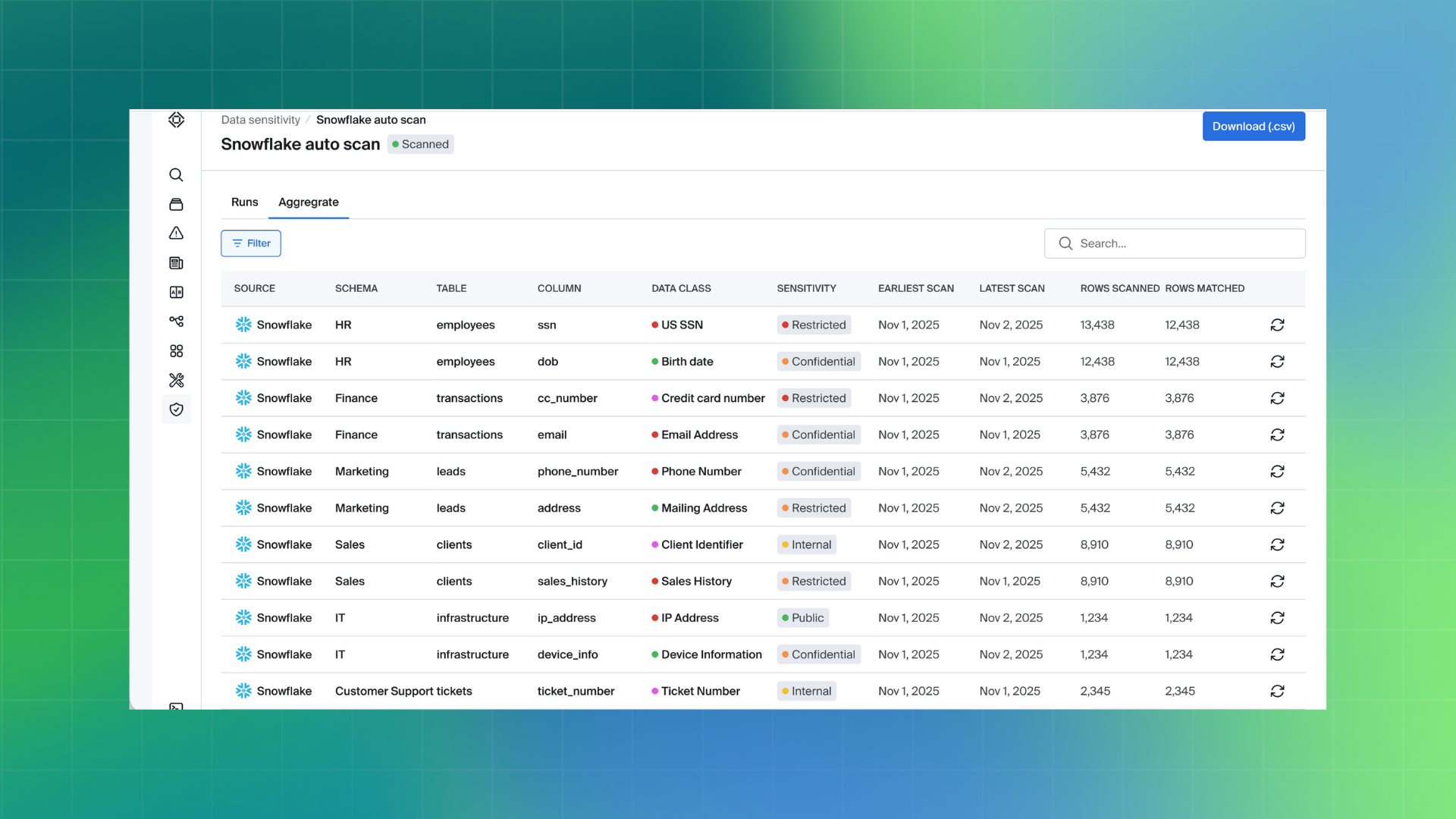
By presenting results in an aggregated format, Bigeye reduces the manual effort required to interpret scan outcomes and prioritize follow-up actions, such as investigation, remediation, or policy enforcement.
Understanding Root Cause With Lineage
Bigeye’s Sensitive Data Scanning builds on its existing data lineage capabilities to provide additional context for sensitive data findings. In addition to identifying and classifying sensitive data, Bigeye helps teams understand where that data originated, how it moved through the data ecosystem, and which downstream assets may be affected.
When sensitive data such as PII, PHI, or PFI is discovered, context is critical. Rather than viewing findings in isolation, Bigeye traces data propagation across upstream and downstream sources, including on-premises, hybrid, and cloud environments. This makes it easier to determine whether sensitive data is contained to a single location or has spread across multiple systems.
Lineage also adds historical and operational context to sensitive data findings. Teams can review how data has changed over time, understand when sensitive fields were introduced, and assess how long the data may have been exposed. This additional context helps data, security, and compliance teams evaluate risk more effectively and prioritize response actions.
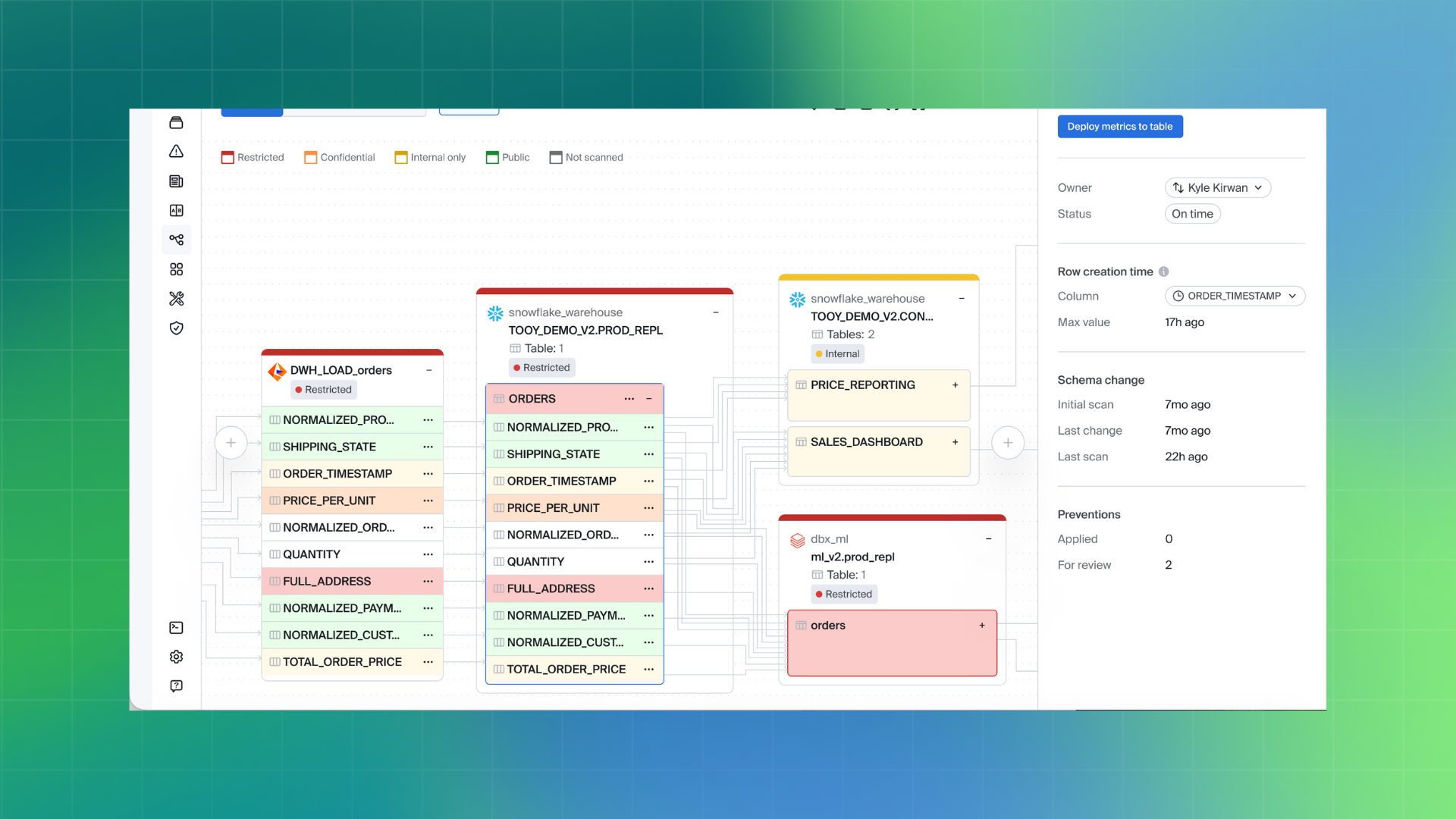
By combining sensitive data scanning with lineage, Bigeye enables teams to move beyond detection and toward understanding—supporting faster investigation and more informed decision-making.
Operationalizing Scanning
Operationalizing sensitive data scanning in Bigeye means establishing a process that is sustainable, cost-effective, and capable of providing end-to-end context for sensitive data across the organization. Rather than treating scans as one-off events, teams can design scanning strategies that align with where risk is highest and where data changes most frequently.
For most organizations, this starts with incremental scanning. By scanning only new or modified data instead of repeatedly rescanning entire datasets, teams can significantly reduce compute costs while keeping sensitive data findings up to date. When paired with lineage, incremental scans can automatically adjust scope as data changes, expanding when sensitive data propagates and narrowing when it is contained. This allows teams to focus effort where it matters most without manual intervention.
Other scan types like full, auto, and sampled scans still play an important role when used intentionally. Full scans are commonly run during initial setup, before audits, or when onboarding new data platforms to establish a complete baseline. Sampled scans can be useful for exploratory analysis on large datasets, while auto scans help maintain ongoing visibility with minimal configuration.
Operationalizing sensitive data scanning is ultimately about choosing the right scan type for the situation at hand. By combining targeted scan strategies with lineage context, teams can better understand where sensitive data lives, why it exists in certain systems, and how to address potential risks as data evolves.
With that information, businesses can de-risk scaling new initiatives and get a quicker and higher return on investment.
Do you know where your sensitive data is? Learn more about Bigeye’s sensitive data scanning module and how to enable analytics and AI initiatives securely with compliance.
Monitoring
Schema change detection
Lineage monitoring

Skailar Hage


.png)

