Why Data Reliability Needs An Operating Model (Not More Alerts)
Data teams often rely on alerts and job monitoring, but that approach misses the real reliability risks: data that flows successfully yet is incomplete, late, or wrong. In this guest perspective, Gaurav Rastogi, Senior Director of Data Analytics at Hertz, illustrates that organizations need a data reliability operating model, built around prevention, detection, diagnosis, correction, and learning in order to protect trust in analytics and AI.
.png)
.png)
Get the Best of Data Leadership
Stay Informed
Get Data Insights Delivered
Disclosure: This article reflects my professional experience and observations. Any organizational examples are generalized to avoid sharing confidential or proprietary details. Bigeye is referenced as the observability platform used to help operationalize the framework described.
Every data leader I speak with is being asked some version of the same question: how fast can we move with AI without breaking trust?
That tension has become one of the defining challenges of modern data organizations. Cloud modernization has increased scale and speed, but it has also multiplied complexity: more pipelines, more dependencies, more consumers, and higher expectations for real-time insights. The result is a reliability problem that many enterprises underestimate until it shows up in the most damaging way possible: when executives, customers, or automated systems make decisions using data that was technically available but practically wrong.
This is not an isolated problem. Gartner has estimated that poor data quality costs organizations an average of $12.9 million per year. Data reliability is no longer just an engineering concern; it is a business risk with material consequences.1
Yet most organizations respond to this challenge by adding more dashboards, more thresholds, and more alerts. In my experience, that approach rarely works at scale. It creates noise, fatigue, and reactive firefighting. What's missing is not more monitoring. It's an operating model.
An operating model defines how accountability is structured, how decisions are prioritized, and how feedback improves performance over time. Reliability should not be layered onto pipelines as an afterthought. It should be embedded into how the organization runs.
That realization led me to formalize what I call the Back-of-the-House Data Reliability Model: a framework that treats data pipelines as production systems and embeds reliability into how data organizations operate day-to-day.
Green pipelines don't mean correct data
Most enterprises still define reliability as job success or failure. That approach worked when data environments were smaller and primarily batch-oriented. It breaks down in distributed, cloud-native ecosystems, especially when analytics and AI consume the outputs.
Across industries, the failure modes are strikingly similar:
- Ingestion jobs complete even when source data is incomplete
- Schema changes propagate without triggering system failures
- Data arrives late but only some consumers notice
- Volume shifts appear normal until dashboards are questioned
- AI models continue scoring on degraded or drifting inputs
.png)
None of these scenarios necessarily cause platform outages. But all of them erode trust. And “trust outages” are often more expensive than downtime—because they slow decision-making, force manual validation, and create skepticism toward analytics and AI initiatives.
These recurring patterns expose three structural weaknesses in how most enterprises approach reliability:
- System completion is mistaken for data correctness.
- Static thresholds are treated as intelligence.
- Issues are detected without clear visibility into business impact.
This pattern comes up repeatedly when I discuss data reliability in industry panels and leadership roundtables. When the problem is named clearly, the reaction is immediate: heads nod, eyes light up,
and the conversation shifts from tooling to accountability. Leaders recognize the issue because they are already living it.
.png)
The industry needs a shift from monitoring to reliability engineering
The reliability leap the industry needs is not incremental. It is a shift from reactive monitoring to proactive reliability engineering.
Traditional monitoring focuses on whether systems ran. A reliability operating model focuses on how data behaves, who is impacted, and how issues can be prevented before they affect decisions. Instead of static thresholds, it emphasizes learned baselines. Instead of manual tracing, it relies on lineage and impact awareness. Instead of firefighting, it builds learning back into the system so reliability improves over time.
This shift is what distinguishes organizations that scale analytics and AI responsibly from those that struggle with constant trust problems. Monitoring asks, "Did something fail?" An operating model asks, "How do we prevent failure, understand impact, and continuously improve?" Reliability moves from a reactive support function to a core engineering discipline.
The Back-of-the-House Data Reliability Model
.png)
I call it “Back-of-the-House” because reliability, like operational excellence in hospitality or manufacturing, happens behind the scenes—but determines everything the customer ultimately experiences. When the back-of-the-house is disciplined, the front-of-the-house runs smoothly. When it is not, trust erodes quickly.
The Back-of-the-House Data Reliability Model organizes reliability into five integrated layers. It is intentionally practical: something that can be adopted incrementally without redesigning an entire platform.
Each layer addresses a distinct failure mode in modern data ecosystems. Together, they form a closed-loop reliability system that reduces uncertainty, accelerates response, and builds institutional knowledge over time.
Here’s how I describe the five layers when I’m speaking to executives:
Prevention: reliability starts before failure
Most organizations begin with alerting. Prevention asks a different question: What does normal look like? By learning baseline patterns for freshness, volume, and distribution, teams can detect weak signals early—before issues propagate downstream. This is where AI belongs in reliability: adaptive baselining that reduces false positives and surfaces subtle drift.
Detection: move beyond “did the job run?”
Detection must focus on behavioral dimensions that matter to consumers: timeliness, completeness, schema integrity, and distribution changes. These are the issues that break trust without breaking pipelines. Detecting them early changes the entire incident lifecycle.
Diagnosis: lineage turns uncertainty into clarity
When an anomaly appears, speed matters. Lineage enables teams to understand not just what changed, but what is affected. Instead of asking which dashboards or models might be impacted, teams can see the dependency path immediately and prioritize response accordingly. This is the difference between reactive scrambling and controlled triage.
Correction: prioritize remediation using impact
Not every issue deserves the same response. Impact-aware remediation helps teams focus on what is truly business-critical. Guided workflows and standardized playbooks reduce chaos while preserving human judgment where it matters most.
Learning: reliability improves over time
Reliability should get quieter as it matures. Every resolved issue feeds back into detection logic, refining sensitivity and reducing noise. Over time, reliability becomes a discipline embedded into daily operations—not something activated only during crises.
Individually, each layer strengthens a different point in the lifecycle. Integrated together, they transform reliability from a collection of controls into an adaptive operating system for enterprise data.
Observability is necessary but not sufficient
Data observability has been an important step forward, providing much-needed visibility into the health and behavior of modern data systems. But visibility alone does not guarantee reliability. The next evolution is embedding observability into a predictive reliability operating model.
As AI adoption accelerates, data quality issues no longer just affect downstream dashboards. They affect automated decisions, forecasts, and customer outcomes. AI systems don't question their inputs. They amplify them. That reality raises the bar for reliability. Organizations that treat reliability as an operating model rather than an after-the-fact check are better positioned to scale AI with confidence, manage risk, and maintain executive trust.
This evolution requires leadership alignment. Reliability cannot live only within engineering teams. It must be visible at the executive level, tied to decision systems, and measured as rigorously as financial or operational performance.
Reliable systems create measurable business value in four ways
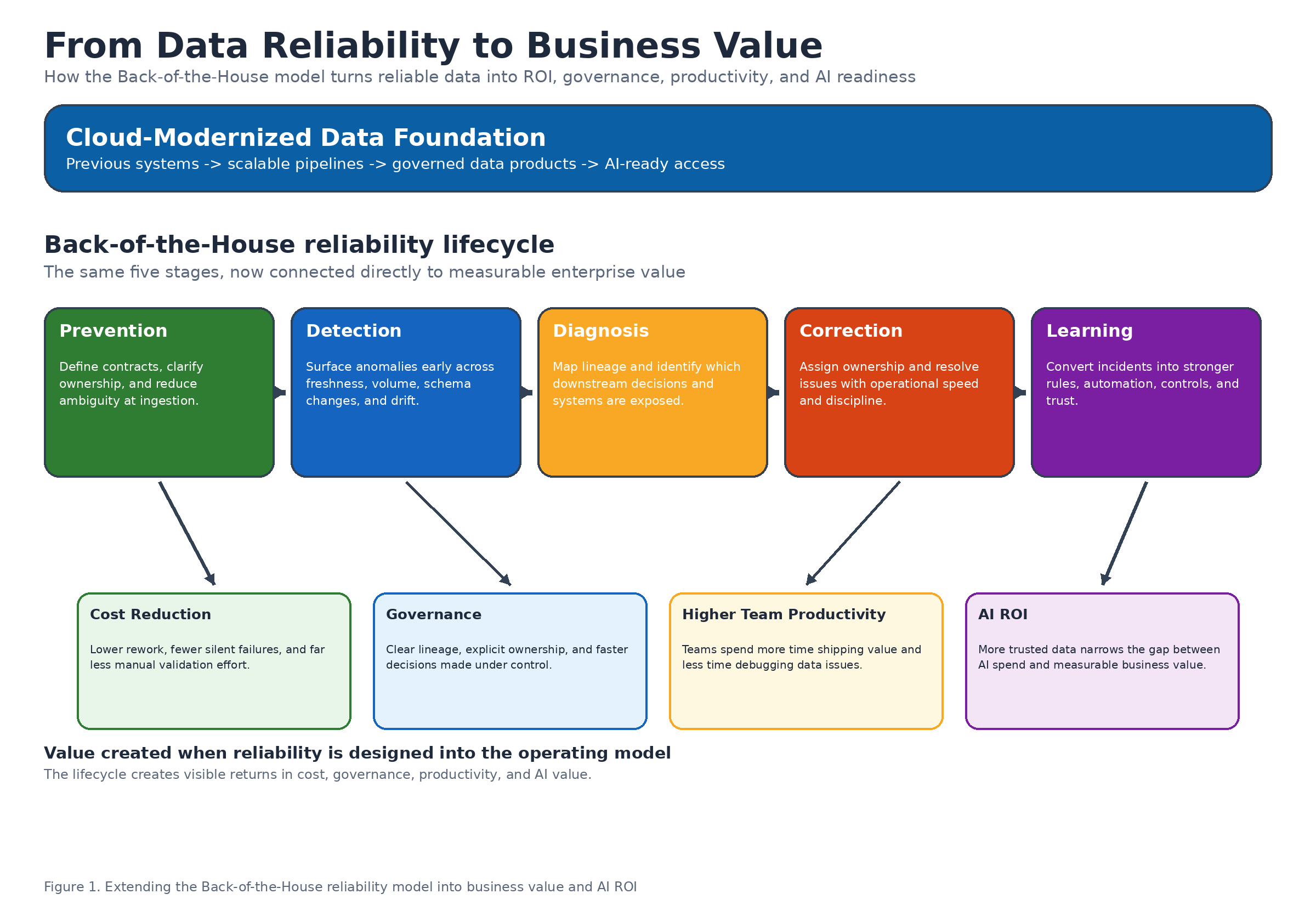
The question organizations were asking when this model was first introduced was: how do we make our data reliable? The question now is: what is a reliable data system worth?
Reliability is not the end state. It is the condition that makes measurable business value possible. The five-layer lifecycle maps directly to four outcomes that matter at the executive level.
Cost efficiency. Reliable systems reduce the compounding operational costs that unreliable ones generate: rework across downstream pipelines, repeated analyst validations, and late-stage failures that are always more expensive to resolve than earlier ones. This is typically the first ROI lever organizations can quantify, and the one that makes the business case for investment in the operating model itself.
Governance that runs operationally. When ownership is explicit and lineage is actionable, governance stops producing compliance artifacts and starts driving decisions. Research published in 2026 reports that 72% of organizations with strong data governance make decisions 25% faster.2 The mechanism is direct: governance embedded into execution is different from governance that exists in documentation.
Team productivity. When issues surface earlier and root cause is clearer, resolution is structured rather than reactive. Engineering capacity consumed by incident response becomes available for building. The shift from firefighting to lifecycle discipline shows up directly in how teams spend their time.
AI ROI. AI outcomes are directly coupled to data reliability. When the underlying data system is reliable, model outputs require less manual verification, deployment friction decreases, and organizational trust in automation builds. AI programs stall more often due to data readiness problems than model limitations: not because the models are wrong, but because teams can't be confident in what they're feeding them.
The five layers form a reinforcing system

These four outcomes don't accumulate independently. They form a reinforcing system. Cloud modernization improves access and scalability. A reliable data layer ensures that data can be trusted at that scale. Strong governance programs improve decision quality. AI outcomes become more consistent and require less oversight. Team productivity increases, enabling faster iteration. The next modernization cycle starts from a stronger foundation.
One assumption worth correcting: cloud modernization alone doesn't produce this outcome. Nucleus Research has measured 328% to 413% ROI within three years for cloud data infrastructure modernization, with an average payback period of four months.3 Those are real returns. But organizations that migrate data infrastructure to cloud platforms without a reliability operating model routinely carry old inefficiencies into a faster environment. Cloud provides scalability, performance, and integration. It doesn't provide the operating rhythms, ownership structures, or data consistency that reliability requires. Without a reliability model, problems scale faster and propagate further.
The underlying shift is from optimizing for data quality to optimizing for decision quality. Reliable data matters when it improves decision outcomes, reduces uncertainty, and enables confident execution. The Back-of-the-House model works because it connects data to signals, signals to decisions, and decisions to outcomes.
Where to start without redesigning everything
If you're a data leader working through where to begin, here's how I'd approach it without boiling the ocean:
Identify your decision systems. Not every dataset matters equally. Define the dashboards, metrics, and AI use cases that leadership depends on. Those are your tier-zero reliability assets.
Implement behavioral detection on those assets: freshness, volume, and schema drift. This is where modern observability platforms help operationalize detection at scale, including adaptive thresholding. Bigeye's platform is built specifically for this layer.
Add lineage for impact visibility. The goal isn't just detecting anomalies; it's being able to answer, in minutes, "what breaks if I don't act?"
Formalize the operating rhythm: who triages, how incidents are classified, how communication happens, and how learnings feed back into the system. Reliability isn't a dashboard. It's a management system.
Closing thoughts
The most common misconception in the industry is that data reliability is a tooling problem.
When data incidents occur, the immediate response is often to ask: do we need better alerts? A different platform? More checks? Those are reasonable questions, but they address the surface of the issue.
The deeper challenge is not the absence of tools. It is the absence of structure.
Reliability breaks down when there is no clear definition of what matters most, no shared understanding of impact, and no disciplined feedback loop that improves the system over time. Tools can surface signals. They cannot define accountability or enforce operational rigor.
Many organizations are fighting the wrong battle. They are optimizing for visibility when the real requirement is operational design.
The organizations that scale AI and advanced analytics successfully are not distinguished by how many alerts they generate. They are distinguished by how deliberately they engineer reliability into how decisions are supported, prioritized, and improved.
Reliability is not a feature to be added. It is a system to be designed.
Monitoring
Schema change detection
Lineage monitoring
Gaurav Rastogi

.png)
.png)
